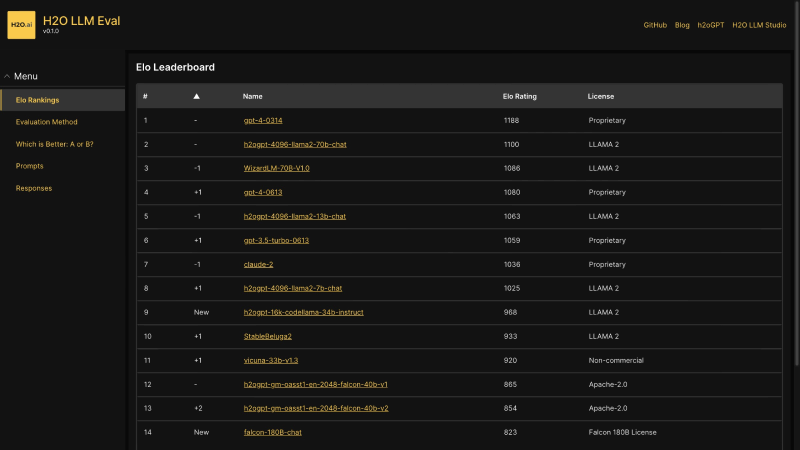
H2O.ai推出的H2O EvalGPT基于Elo评级方法评估大模型性能确保公正性和准确性
《MMBench》:全面评估多模态大模型能力的权威评测体系
复旦大学NLP实验室推出的【LLMEval3】是针对大型语言模型的全面评测基准
中文通用大模型综合性测评基准《SuperCLUE》旨在全面评估和优化大模型的性能和应用效果
Hugging Face推出的开源大模型排行榜,展示最新最全的模型性能对比。
斯坦福大学推出的大模型评测体系《HELM》旨在全面评估AI模型的性能和可靠性
一个全面评估大模型中文能力的基准应用,涵盖多项专业领域测试,详见《CMMLU》。